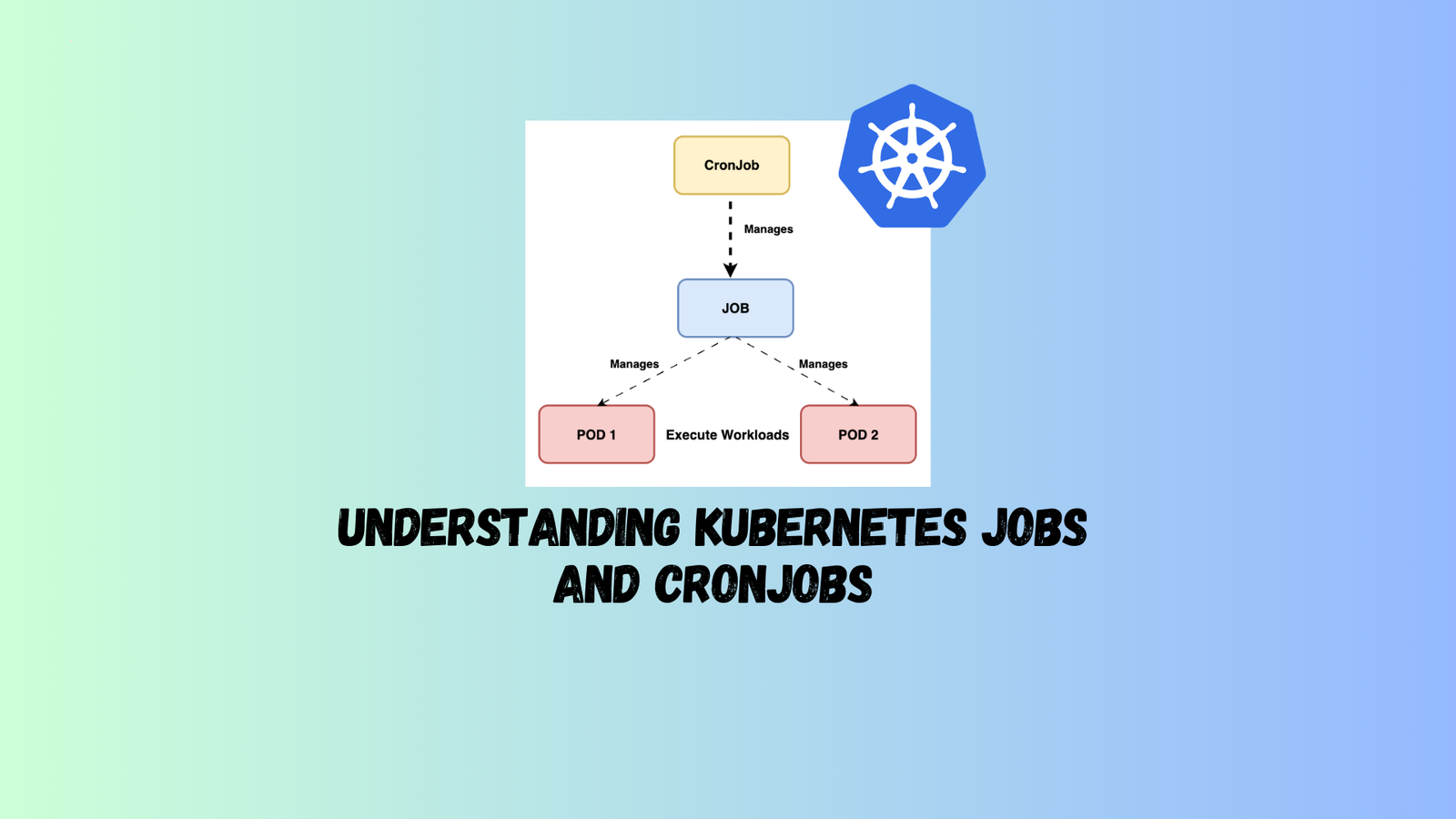
A Kubernetes Job is for a one-off task, wrapping up once it’s done. Think of it as a “do it and drop it” deal. CronJobs, however, are the repeat performers, scheduled to run tasks at regular intervals, like daily data backups.
We’ll cover how to set up, kick off, and peek into both Jobs and CronJobs to keep your work flowing.
Working with Kubernetes Jobs
In Kubernetes, a Job is a basic element designed to run tasks until a certain number of them are completed. It’s perfect for one-off jobs like moving data in and out or handling tasks that have a clear end, especially if they’re heavy on input/output operations.
The real action happens inside a Pod, where the work gets done. You can think of a Job as a manager overseeing Pods that carry out the tasks. There’s a kind of parent-kid dynamic where the Job is the parent, making sure its Pod “children” get the work done right.

After a Job in Kubernetes is done, it and its Pods aren’t automatically removed. They stay put until you delete them. This is useful for checking out logs and figuring out what happened during the Job, helping with troubleshooting.
Creating and Inspecting Kubernetes Jobs
Let’s dive into the world of Kubernetes Jobs, starting with the creation process and then moving on to inspection. To create a Job directly, you’ll typically use the kubectl create job command. If your selected image is passive and doesn’t inherently execute commands, you’ll need to specify what command it should run within its Pod.
Here’s a hands-on example: we’re creating a Job named ‘counter’ designed to execute a simple iterative process. In this process, a ‘counter’ variable is incremented with each loop iteration until it reaches a total count of 3:
kubectl create job counter --image=nginx:1.25.1 \
-- /bin/sh -c 'counter=0; while [ $counter -lt 3 ]; do \
counter=$((counter+1)); echo "$counter"; sleep 3; done;'
For those who prefer a more declarative stance, here’s how you can define the same Job using a YAML manifest (Example 6-1):
apiVersion: batch/v1
kind: Job
metadata:
name: counter
spec:
template:
spec:
containers:
- name: counter
image: nginx:1.25.1
command:
- /bin/sh
- -c
- 'counter=0; while [ $counter -lt 3 ]; do counter=$((counter+1)); echo "$counter"; sleep 3; done;'
restartPolicy: Never
This YAML leverages standard Pod attributes for its template, making it a straightforward extension of Pod configurations.
Observing the Job post-creation reveals its progress and completion status. Initially, Kubernetes may report 0/1 completions, which updates to 1/1 upon successful completion, indicating that the Job has finished as intended. A Job typically operates with a single Pod, identifiable by a name prefix derived from the Job itself:
$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
counter 0/1 13s 13s
$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
counter 1/1 15s 19s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
counter-z6kdj 0/1 Completed 0 51s
To ensure everything ran correctly, you can inspect the Pod’s logs for a detailed account of each iteration:
$ kubectl logs counter-z6kdj
1
2
3logs counter-z6kdj
This output should sequentially list the numbers up to 3, confirming the Job’s successful execution.
Diving Deeper: Job Operation Types and Restart Policies
By default, a Job is designed to complete its task using a single Pod, a setup Kubernetes terms as a non-parallel Job. This behavior and its parameters, such as spec.completions and spec.parallelism, are initially set to 1, indicating a one-off task. Adjusting these parameters allows for more complex Job configurations, including parallel executions and multiple completions, catering to a broader range of use cases.
For example, to expand on the types of Job operations:
- Non-parallel Jobs conclude once their singular Pod finishes successfully.
- Parallel Jobs with a fixed completion count ensure a specified number of tasks are successfully completed.
- Parallel Jobs with a worker queue run until at least one Pod finishes and all initiated Pods have ceased operations.
The spec.backoffLimit attribute is crucial for controlling a Job’s retry logic, specifying how many attempts a Job should make before being deemed unsuccessful.
Furthermore, Jobs require an explicit restart policy (OnFailure or Never) to manage how Pod failures are handled, differing from the default Pod behavior of continual restarts regardless of exit status.
Understanding these dynamics—how to initiate Jobs, inspect their execution, and tailor their operation through configuration adjustments—enhances your Kubernetes mastery, enabling efficient and effective task automation within your clusters.
Working with Kubernetes CronJobs
A Job in Kubernetes is a task that runs until it’s completed. Once it’s done, no more Pods are created for it. A CronJob takes this concept further by scheduling Jobs to be created at regular intervals. It’s like setting an alarm clock for your Jobs, ensuring they run repeatedly according to a timetable. Each Job then oversees the Pods that do the actual work.
Think of a CronJob as the planner, scheduling Jobs, which then manage the Pods that execute the tasks. This setup allows for tasks to be performed not just once, but repeatedly at scheduled times.

You can schedule CronJobs with cron expressions, just like Unix cron jobs. For instance, you can have a CronJob that runs every hour. Each time it runs, it makes a new Pod to do the task, which then finishes successfully or with an error.

Creating and Inspecting CronJobs
Deploying a CronJob in Kubernetes can be efficiently achieved through the use of the kubectl create cronjob command for immediate creation. For instance, to schedule a CronJob that announces the current date every minute, you might use the following command:
kubectl create cronjob current-date --schedule="* * * * *" \
--image=nginx:1.25.1 -- /bin/sh -c 'echo "Current date: $(date)"'
For a more structured approach, defining a CronJob via a YAML manifest offers greater control and clarity. Consider the following manifest (Example 6-2) for a CronJob designed to echo the current date:
apiVersion: batch/v1
kind: CronJob
metadata:
name: current-date
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: current-date
image: nginx:1.25.1
args:
- /bin/sh
- -c
- 'echo "Current date: $(date)"'
restartPolicy: OnFailure
This setup not only defines the cron expression for scheduling but also elaborates on the job template specifying the task to be executed.
To inspect active CronJobs and their schedules, kubectl get cronjobs provides a snapshot of your CronJobs, displaying schedules, activity, and the timing of the last job run:
kubectl get cronjobs
Identifying jobs and pods spawned by a CronJob is straightforward, with naming conventions typically following a prefix pattern based on the CronJob name.
Tailoring Job History Preservation
By default, a CronJob keeps a record of the last three successful runs and the last failure, aiding in debugging and log analysis. These settings can be adjusted to suit different operational needs:
kubectl get cronjobs current-date -o yaml | grep successfulJobsHistoryLimit:
kubectl get cronjobs current-date -o yaml | grep failedJobsHistoryLimit:
To modify these settings, adjust the spec.successfulJobsHistoryLimit and spec.failedJobsHistoryLimit in your CronJob’s YAML definition. For instance, to retain the last five successes and three failures:
apiVersion: batch/v1
kind: CronJob
metadata:
name: current-date
spec:
successfulJobsHistoryLimit: 5
failedJobsHistoryLimit: 3
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: current-date
image: nginx:1.25.1
args:
- /bin/sh
- -c
- 'echo "Current date: $(date)"'
restartPolicy: OnFailure
This approach not only streamlines task scheduling and execution in Kubernetes but also ensures operational insights are preserved for analysis and troubleshooting
Conclusion
In summary, Kubernetes Jobs are ideal for batch processes in one or multiple Pods, staying around after completion for review and debugging. CronJobs are similar to Jobs but run on a schedule set by Unix cron expressions, perfect for regular, automated tasks.






