Introduction
In order to solve the problem of poor performance of large language models, people have previously focused on retraining, fine-tuning, and prompt enhancement of large models. However, there is no better solution for proprietary and rapidly updated data. Therefore, the emergence of Retrieval Augmented Generation (RAG) bridges the gap between LLM common sense and proprietary data.
The article I’m going to share with you today will introduce the concept of RAG and show you how to use LangChain for orchestration, OpenAI language model, and Weaviate vector database (you can also build your own Milvus vector database ) to implement a simple RAG pipeline.
What is RAG?
RAG stands for Retrieval-Augmented Generation, which is a concept of providing external knowledge sources to large models, which enables them to generate accurate and contextual answers while reducing model hallucinations.
Knowledge update issues
The most advanced LLMs accept a large amount of training data and store a wide range of common sense knowledge in the weights of the neural network. However, when we prompt the large model to generate knowledge beyond the training data, such as the latest knowledge, domain-specific knowledge, etc., the output of the LLM may lead to inaccurate facts, which is what we often call model hallucination. As shown in the figure below:

Therefore, it is important to bridge the gap between the common sense of large models and other background knowledge to help LLM generate more accurate and contextual results while reducing hallucinations.
Solution
The traditional solution is to fine-tune neural network models to fit domain-specific proprietary information. Although this technique is effective, it is computationally intensive and requires technical expertise, making it difficult to flexibly adapt to changing information.
In 2020, Lewis et al. proposed a more flexible technique called Retrieval-Augmented Generation (RAG) for knowledge-intensive NLP tasks [reference paper: https://arxiv.org/abs/2005.11401]. In this paper, the researchers combined the generative model with the retriever module to provide additional information from external knowledge sources, and this information can be easily updated and maintained.
In simple terms, RAGs for LLM students are like open book exams. In an open book exam, students can bring reference materials, such as textbooks or notes, which they can use to look up relevant information to answer questions. The idea behind open book exams is that the focus of the test is on students’ reasoning ability rather than their ability to memorize specific information.
Likewise, factual knowledge is separated from the reasoning capabilities of the LLM and stored in external knowledge sources where it can be easily accessed and updated:
- “Parameter knowledge” : Knowledge learned during training, implicitly stored in the weights of the neural network.
- “Non-parametric knowledge” : stored in external knowledge sources, such as vector databases.
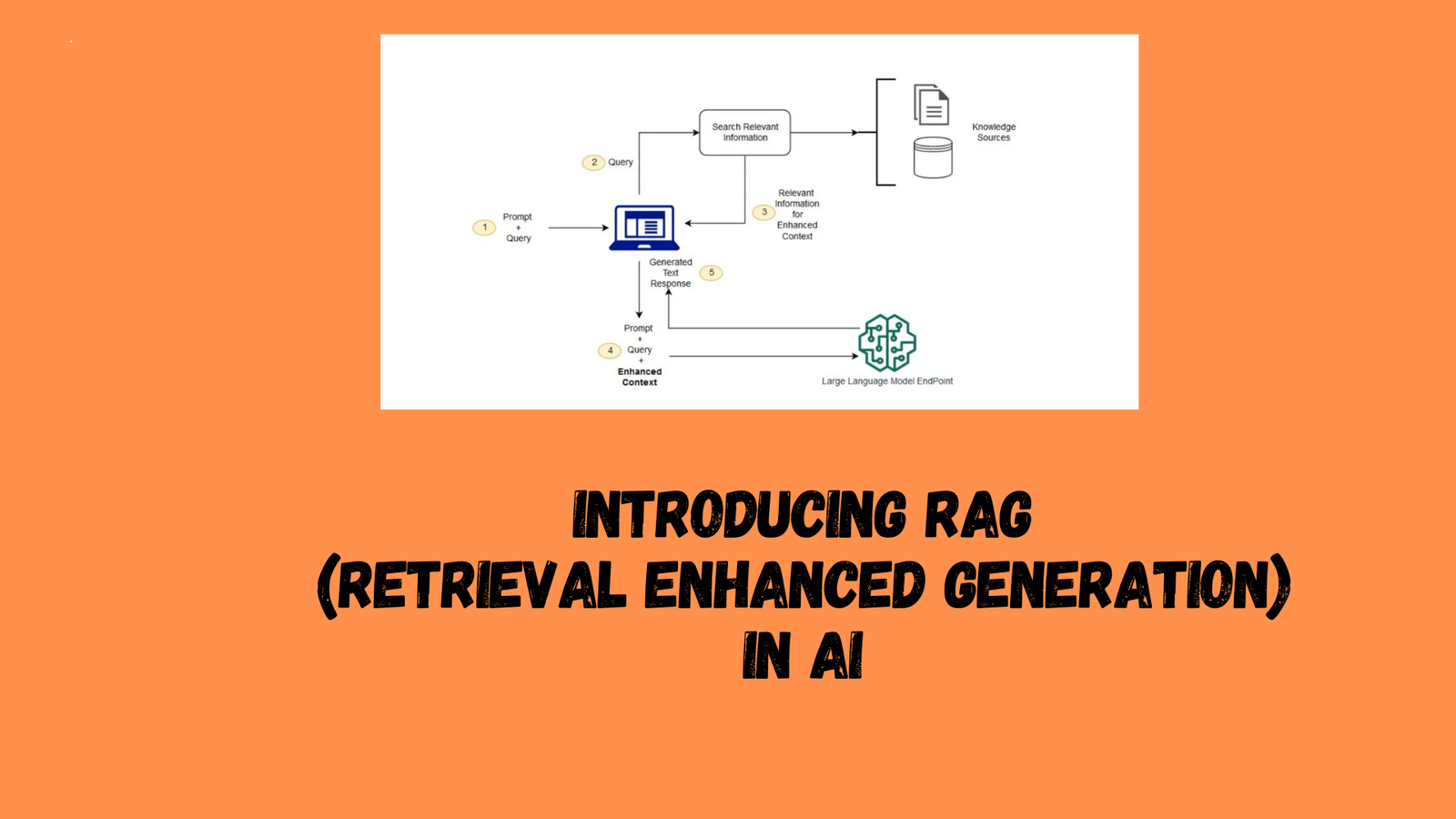
The general RAG workflow is shown in the figure below:

Retrieve retrieves relevant context from external knowledge sources based on user requests. To do this, an embedding model is used to embed the user query into the same vector space as the additional context in the vector database. This allows performing a similarity search and returns the top k closest data objects in the vector database.
Augmentation: The user query and additional context retrieved are populated into the suggestion template.
Generate Finally, the search enhancement hints are fed to the LLM.
LangChain implements RAG
The above introduces the generation and working principle of RAG. Next, we will show how to use LangChain, combined with OpenAI LLM and Weaviate vector database, to implement RAG Pipeline in Python .
Basic environment preparation
1. Install all the required dependent Python packages, including langchain for orchestration, openai, a large model interface, and weaviate-client, a client for the vector database.
pip install langchain openai weaviate-client
2. Apply for an OpenAI account and obtain the OpenAI API key, as shown below:

3. Create a .env file in the project root directory to store relevant configuration files, as shown in the figure below.

4. In the main directory, load the configuration file information. The python-dotenv package is used here.

Vector Database
Next, you need to prepare a vector database as an external knowledge source to store all the additional information. The vector database is populated through the following steps: 1) loading data; 2) data chunking; 3) data chunk storage .
“Load data” : Here, a novel of Dou Po Cangqiong is selected as the document input. The document is a txt text. To load the text, LangChain’s TextLoader is used here.
from langchain.document_loaders import TextLoader
loader = TextLoader('./BattleThroughTheHeavens.txt')
documents = loader.load()
“Data chunking” : Because the document in its original state is too long (nearly 50,000 lines) to fit into the context window of a large model, it needs to be split into smaller parts. LangChain has many built-in splitters for text. Here, CharacterTextSplitter with a chunk_size of about 1024 and a chunk_overlap of 128 is used to maintain text continuity between chunks.
Code language: javascript
copy
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1024, chunk_overlap=128)
chunks = text_splitter.split_documents(documents)
Chunk storage : To enable semantic search across text chunks, you need to generate vector embeddings for each chunk and then store them together with their embeddings. To generate vector embeddings, you can use the OpenAI embedding model and use the Weaviate vector database for storage. By calling .from_documents(), the vector database is automatically populated with chunks.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
RAG Implementation
「Step 1: Data Retrieval」 After storing the data in the vector database, we can define a retriever component that obtains relevant context based on the semantic similarity between the user query and the embedded block.
Code language: javascript
copy
retriever = vectorstore.as_retriever()
「Step 2: Prompt Enhancement」 After completing the data retrieval, you can use the relevant context to enhance the prompt. In this process, you need to prepare a prompt template. You can easily customize the prompt through the prompt template, as shown below.
Code language: javascript
from langchain.prompts import ChatPromptTemplate
template = """You are a Q&A assistant. Please use the following retrieved context to answer the question. If you do not know the answer, just say you do not know. The question is: {question}, context: {context}, the answer is:
"""
prompt = ChatPromptTemplate.from_template(template)“Step 3: Answer Generation” uses the RAG pipeline to build a chain that links the retriever, prompt template, and LLM together. After defining the RAG chain, you can call it.
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query = "Who is JOHN's cousin?"
res = rag_chain.invoke(query)
print(f'Answer: {res}')
In general, the RAG generation process is shown in the following figure:

Conclusion
This article introduces the concept of RAG and some of the theories behind it. This article implements it through Python and LangChain. In the process, OpenAI’s ChatGPT interface (you can build chatGLM3 yourself), Weaviate vector database (you can build Milvus yourself), and OpenAI embedding model are used to implement the RAG pipeline.






